0x00 目标
有个好朋友买了该课程,希望将内容下载下来随时听,问我有没有办法,经过几天探索,终于将该课程的内容下载到了本地。
0x01 获取链接
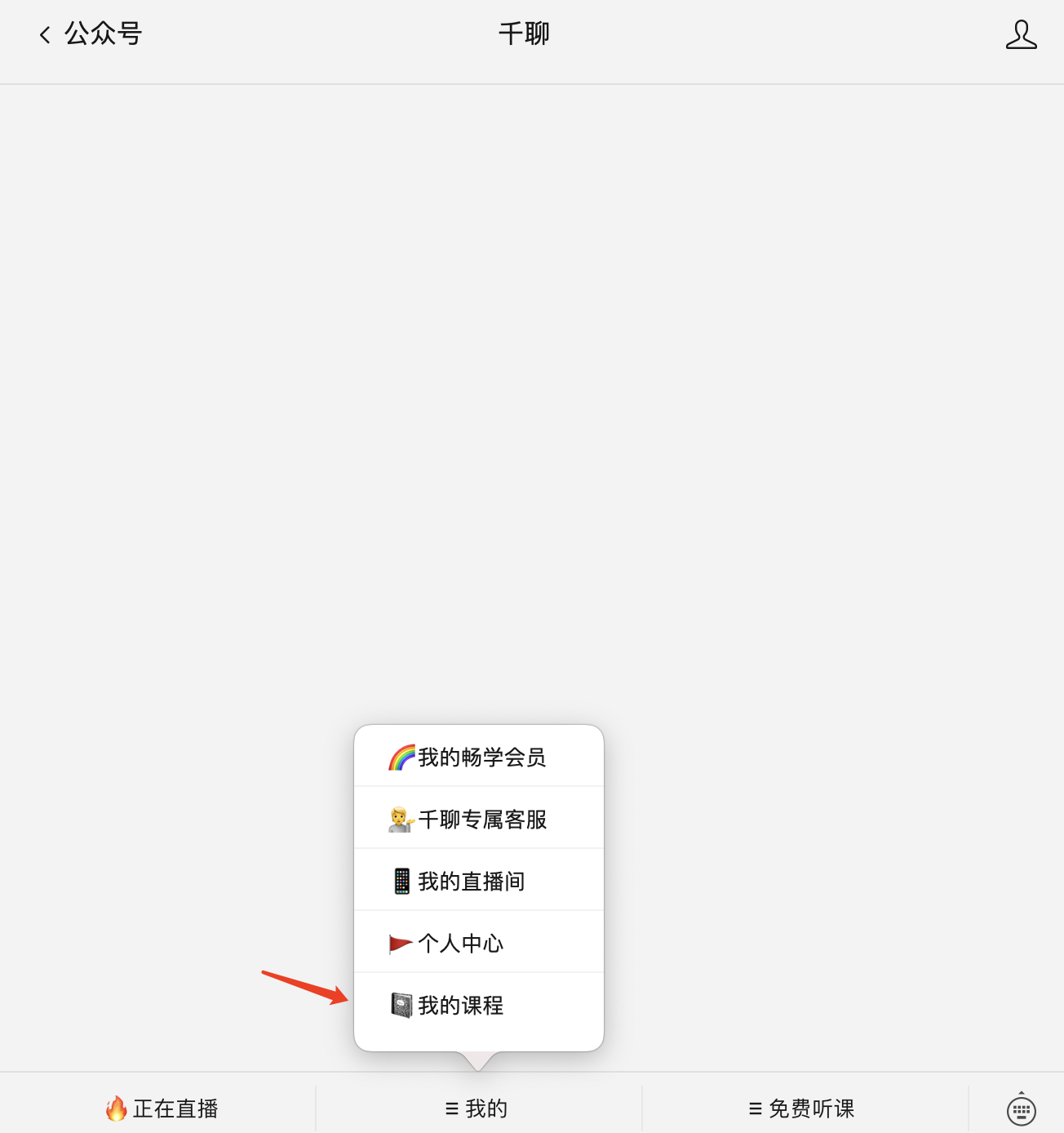
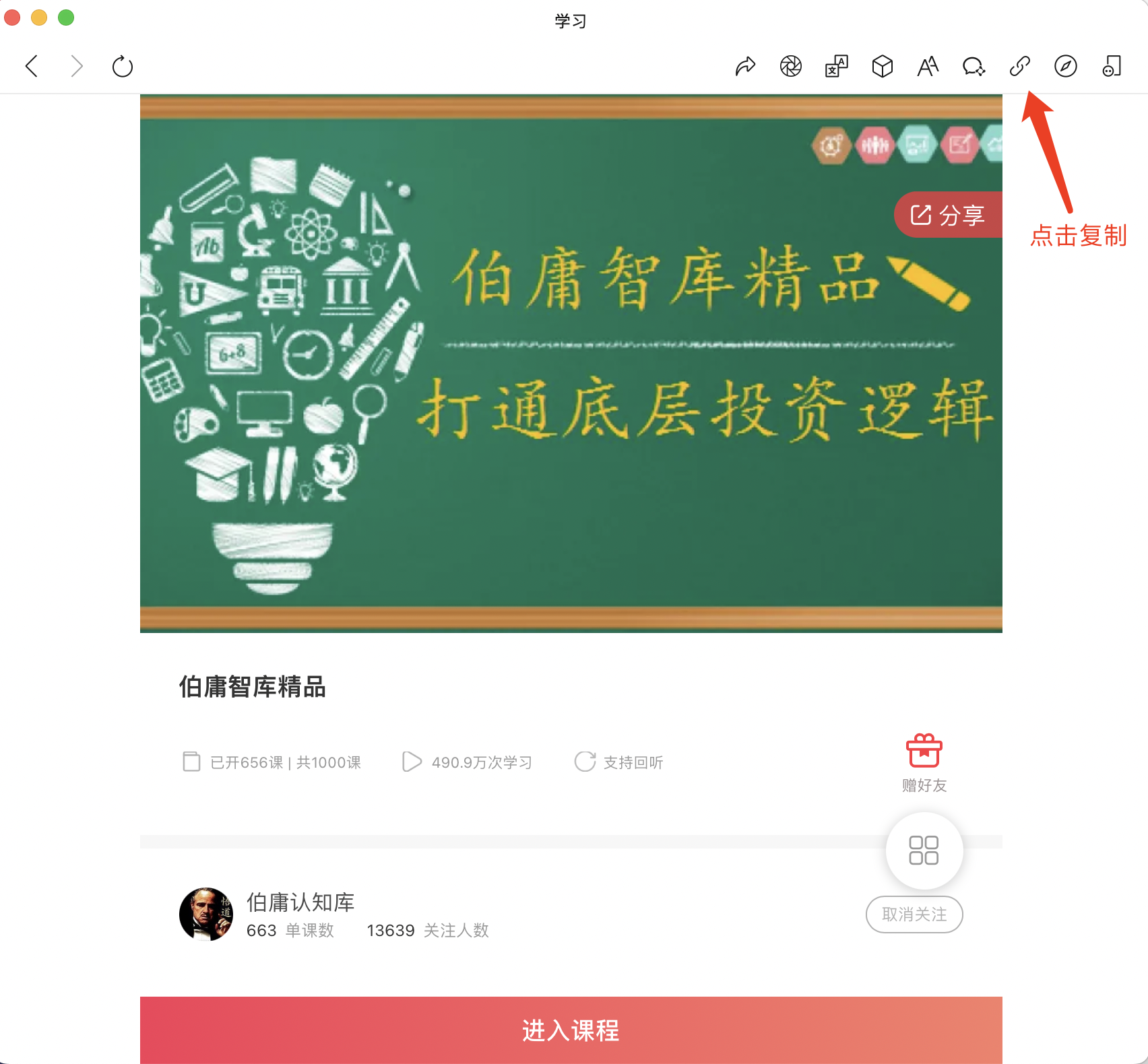
去微信PC端,关注千聊公众号,点我的—>我的课程,选中相应课程,打开之后,点击右上角的复制链接,以伯庸智库为例,对应的课程链接就是:https://m.qlchat.com/wechat/page/channel-intro?channelId=2000007225767060
0x02 在Chrome中打开页面

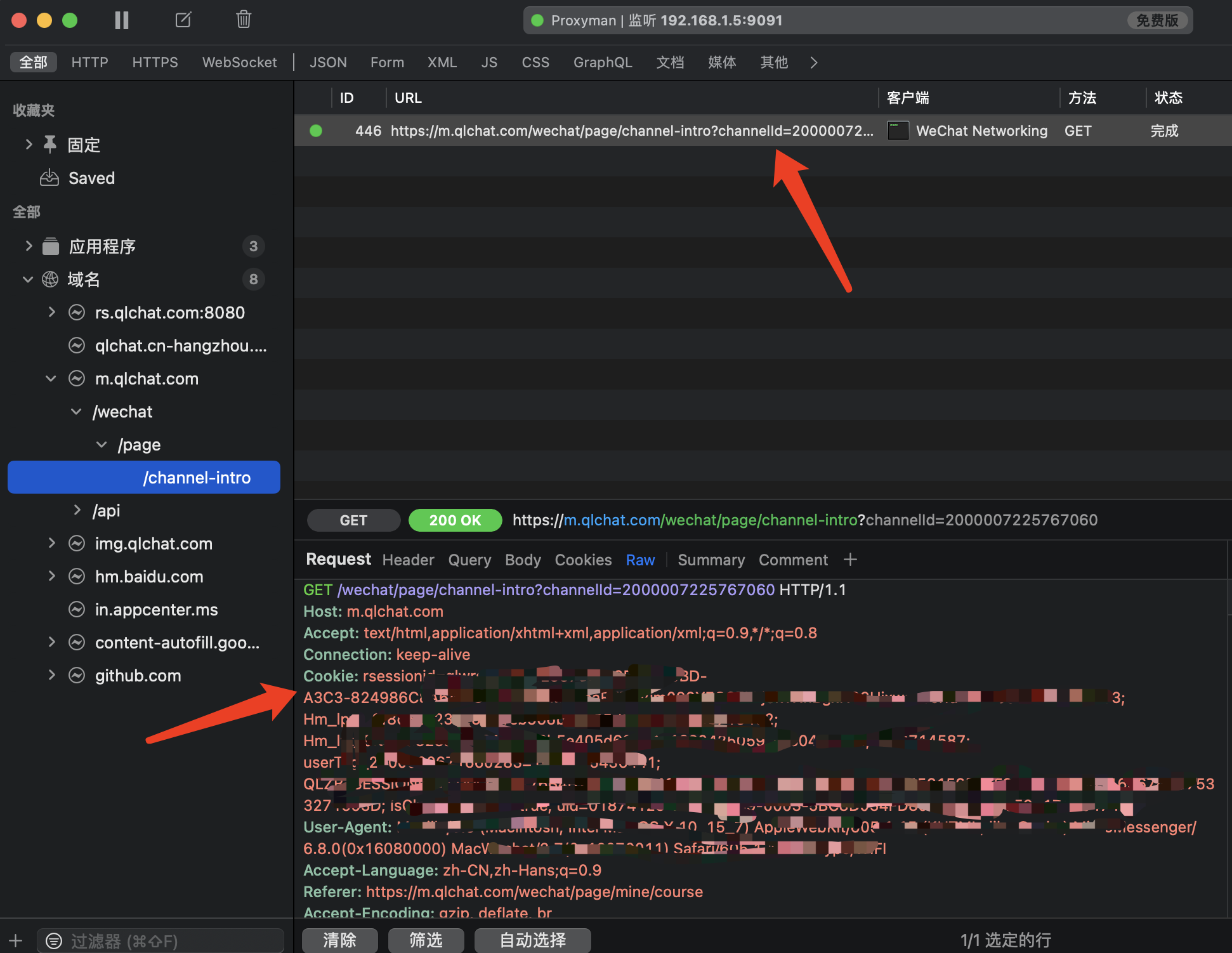
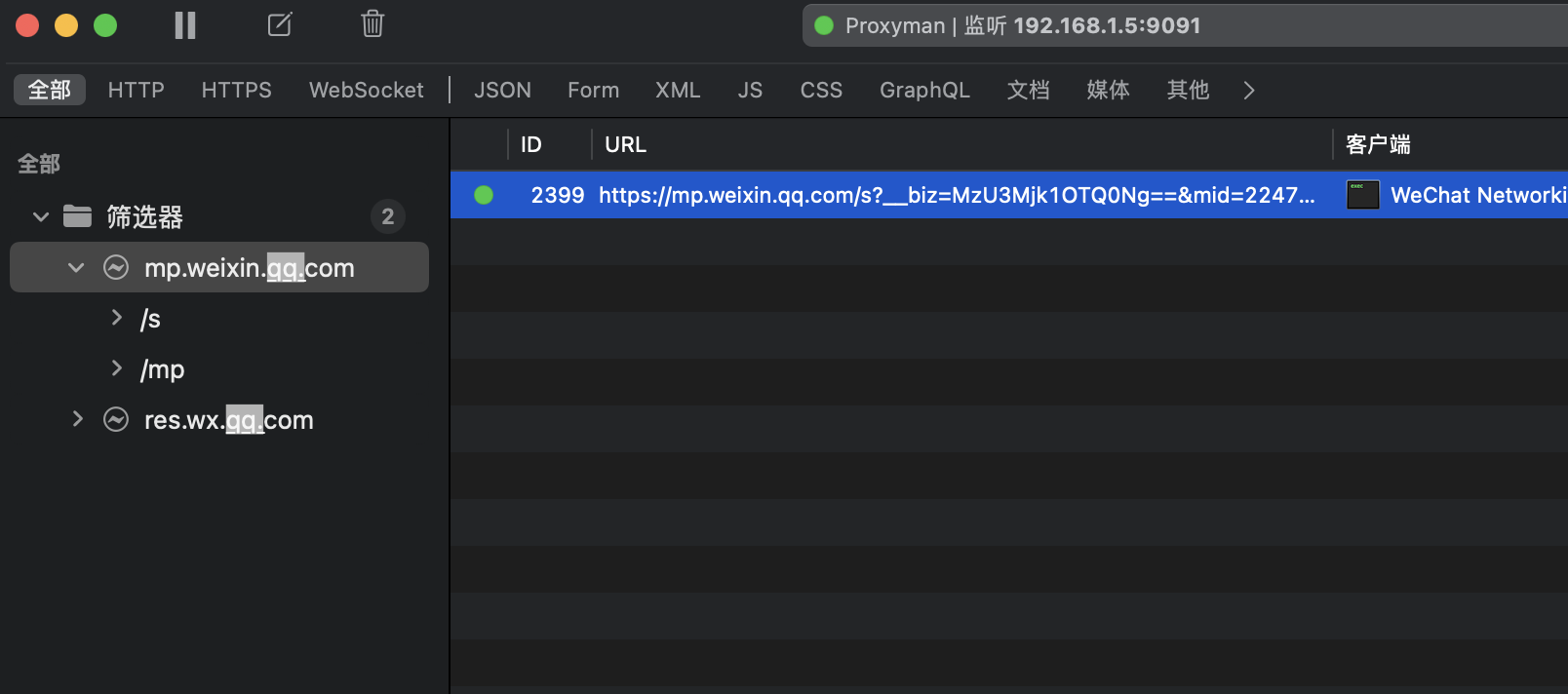
使用Chrome浏览器打开上述链接:https://m.qlchat.com/wechat/page/channel-intro?channelId=2000007225767060,不出意外会告诉你无权限访问。先别着急,去这里下载:https://proxyman.io/ Proxyman软件,安装成功后,回到微信PC端,重新刷新一下该课程的页面,会看到有相应请求,而且请求信息里有最关键的cookie。我们把cookie复制下来。
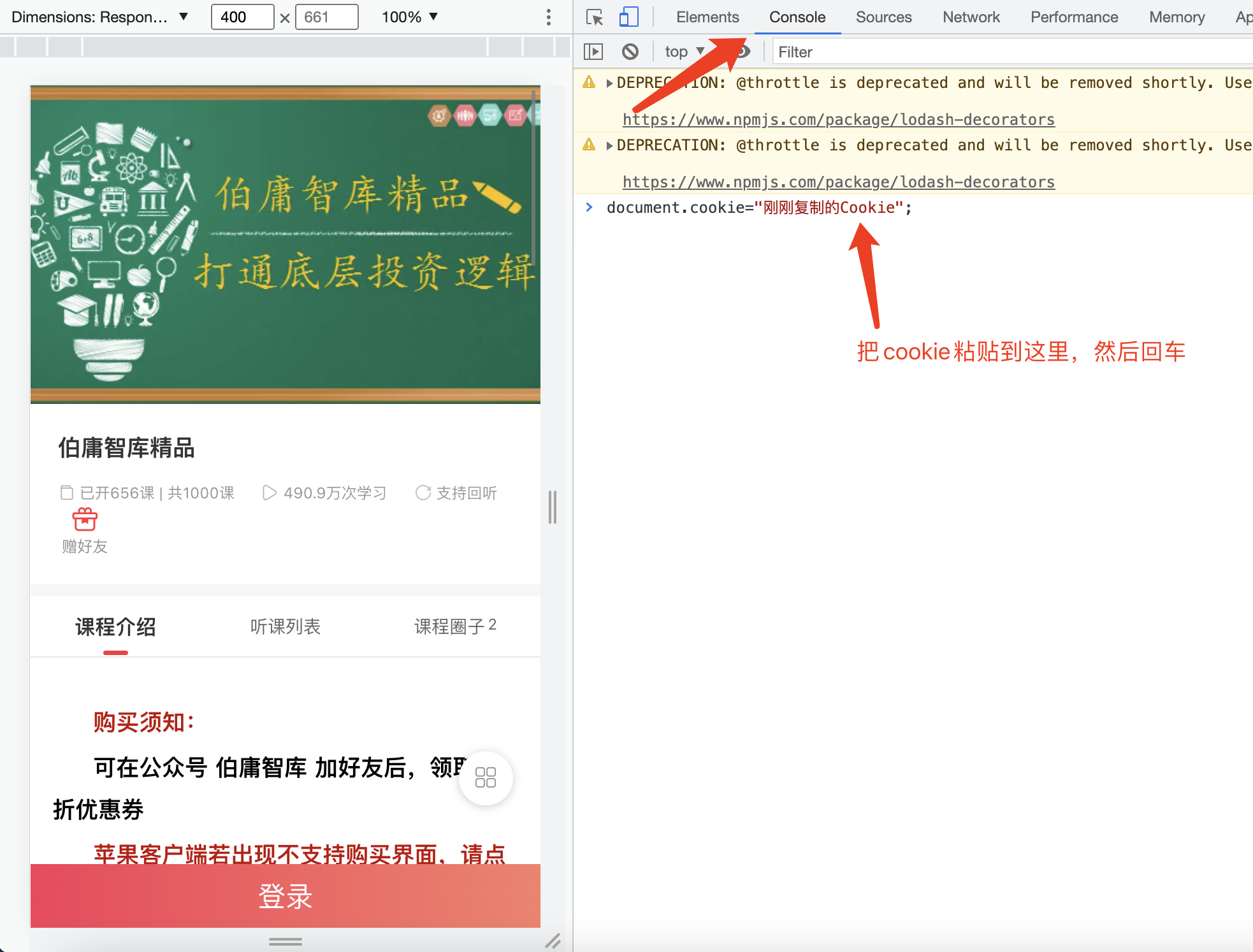
回到Chrome浏览器上,打开开发者工具(Mac直接按option+command+I),点到console这个tab,然后输入document.cookie=”刚刚复制的Cookie”,点回车,刷新一下页面,神奇的事情发生了。你现在已经登录成功了,可以正常在Chrome里浏览相应的内容了。
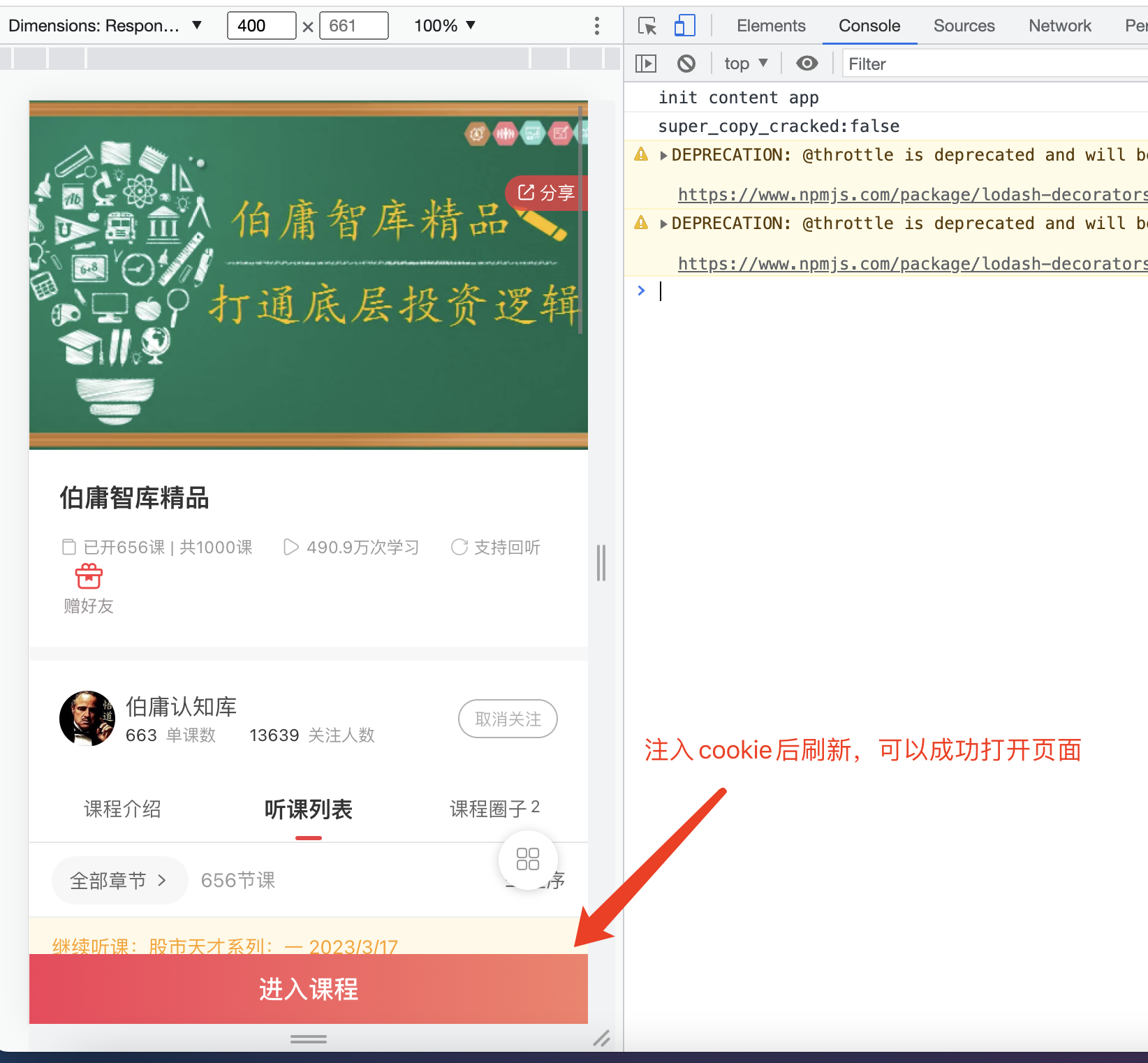
举一反三,你也可以用类似的方式,在PC端的Chrome浏览器打开微信公众号的文章,而且是带有评论的。链接通过抓包可以看到,这里就不再多赘述。
0x03 提取关键信息
正常进入到页面之后,就可以通过Chrome提供的开发者工具分析网络请求信息了。通过逐个请求分析,发现getCourseList接口返回的就是课程的信息。
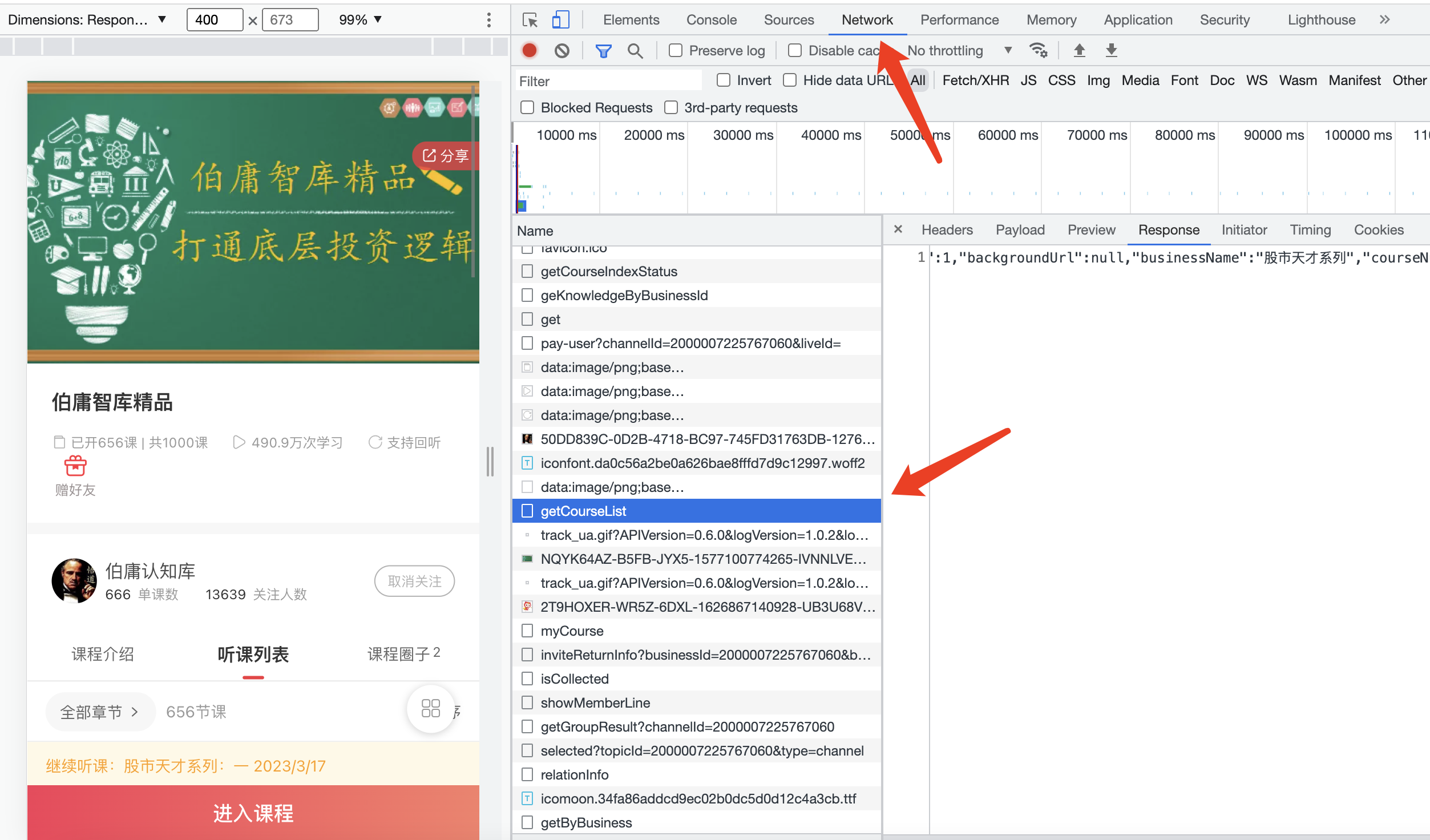
通过对返回信息进行分析发现几个关键信息
- 其中id就是章节id,章节的唯一标识
- topic就是标题名称
- style标识不同类型的内容,如果是视频则为videoGraphic,如果是音频则为videoGraphic
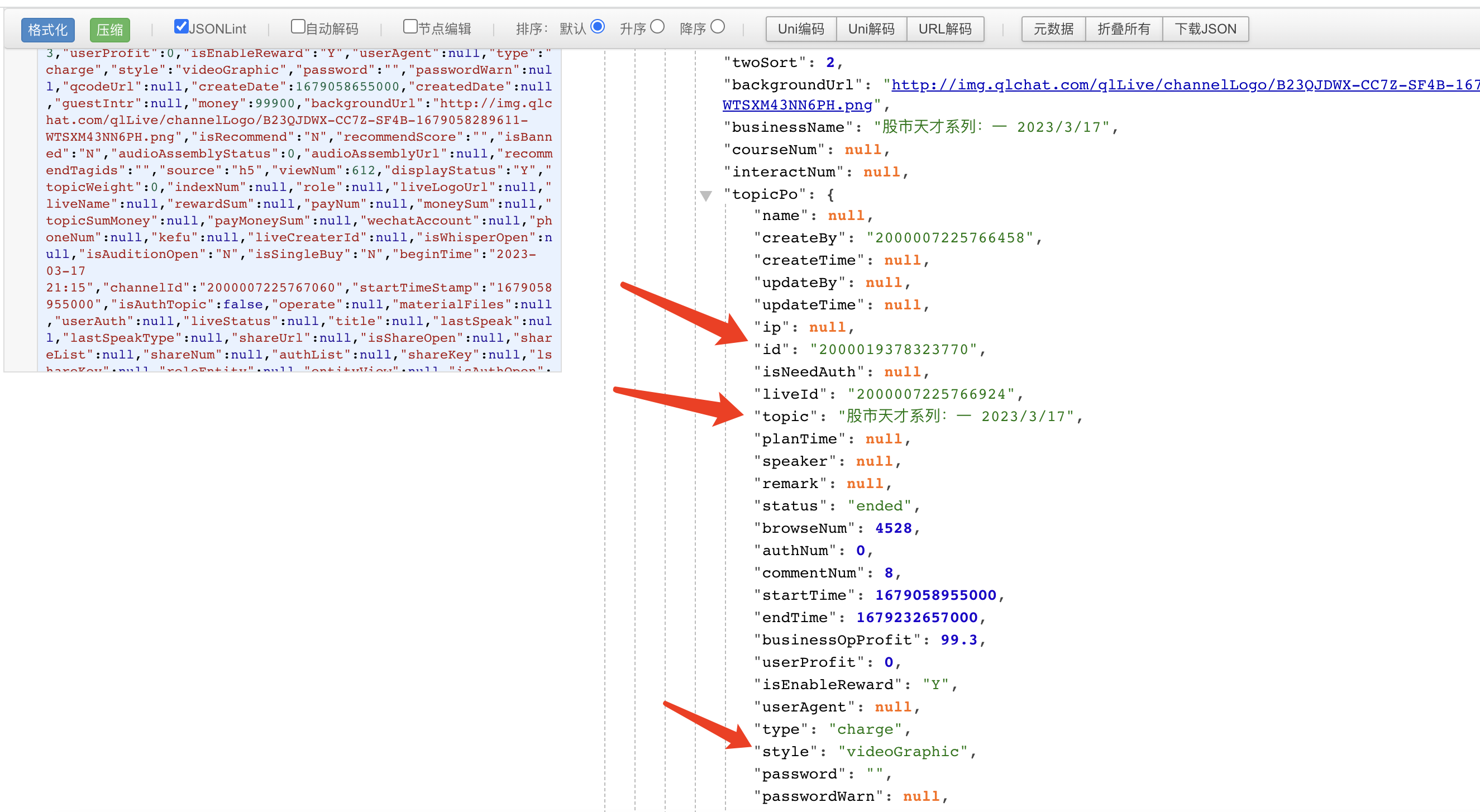
继续点进任意一节课,查看对应的请求信息。
提取视频链接
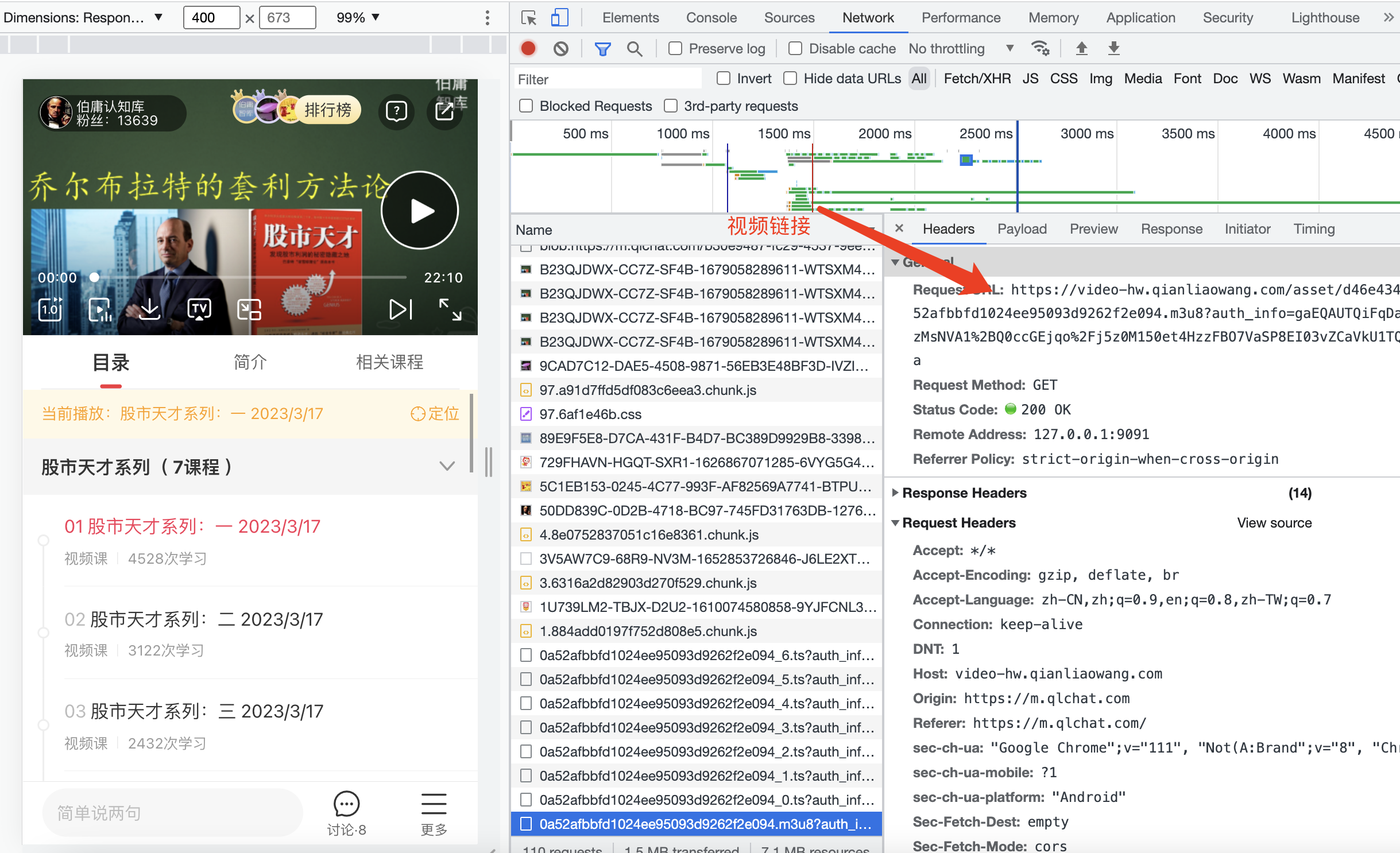
从中找到m3u8的请求,这就是我们想要的链接。真正的播放的视频是.ts的请求,但是我们可以通过m3u8链接拼接出所有的ts文件链接,从而得到所有的ts视频链接,把ts文件全部下载下来,拼接到一起即可。我们可以通过https://m.qlchat.com/wechat/page/topic-simple-video?topicId=拼接上对应的章节id即可打开所有的视频页面,也可以获取到所有的m3u8链接了。
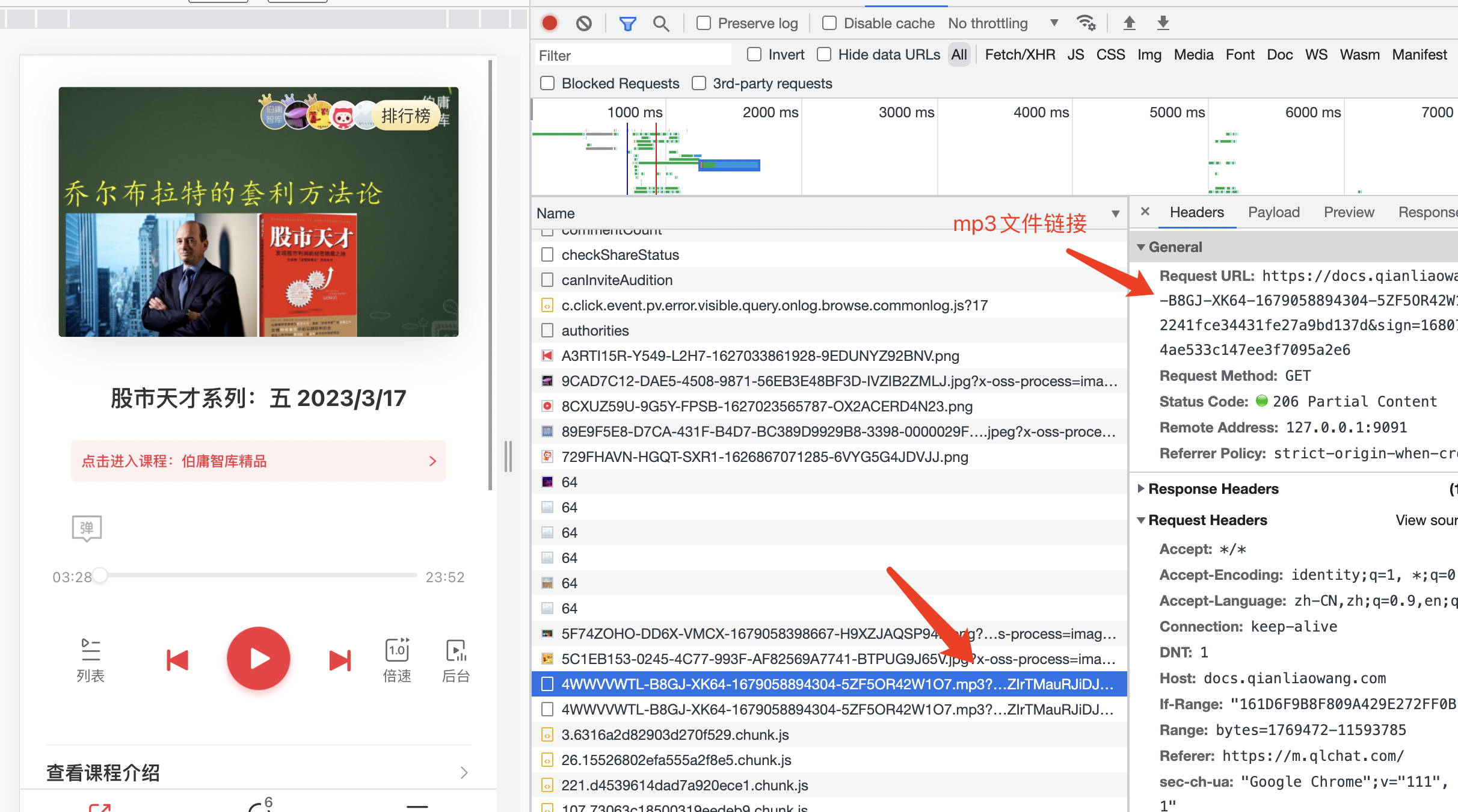
提取音频链接
音频要比视频简单得多,任意打开一个音频课,请求列表里可以看到mp3的请求链接,直接用下载下来就可以播放了。
0x04 自动化
分三步走:
- 先通过getCourseList请求拿到所有的章节id
- 如果是视频,通过Python + Selenium模拟打开https://m.qlchat.com/wechat/page/topic-simple-video?topicId=id;如果音频,则拼接链接为:[https://m.qlchat.com/topic/details-listening?topicId=id](https://m.qlchat.com/topic/details-listening?topicId=2000019378323799)
- 通过Python + Selenium模拟打开对应的页面,获取到页面的所有请求信息,过滤出相应的请求链接(m3u8/mp3),然后去下载即可。
获取所有章节id
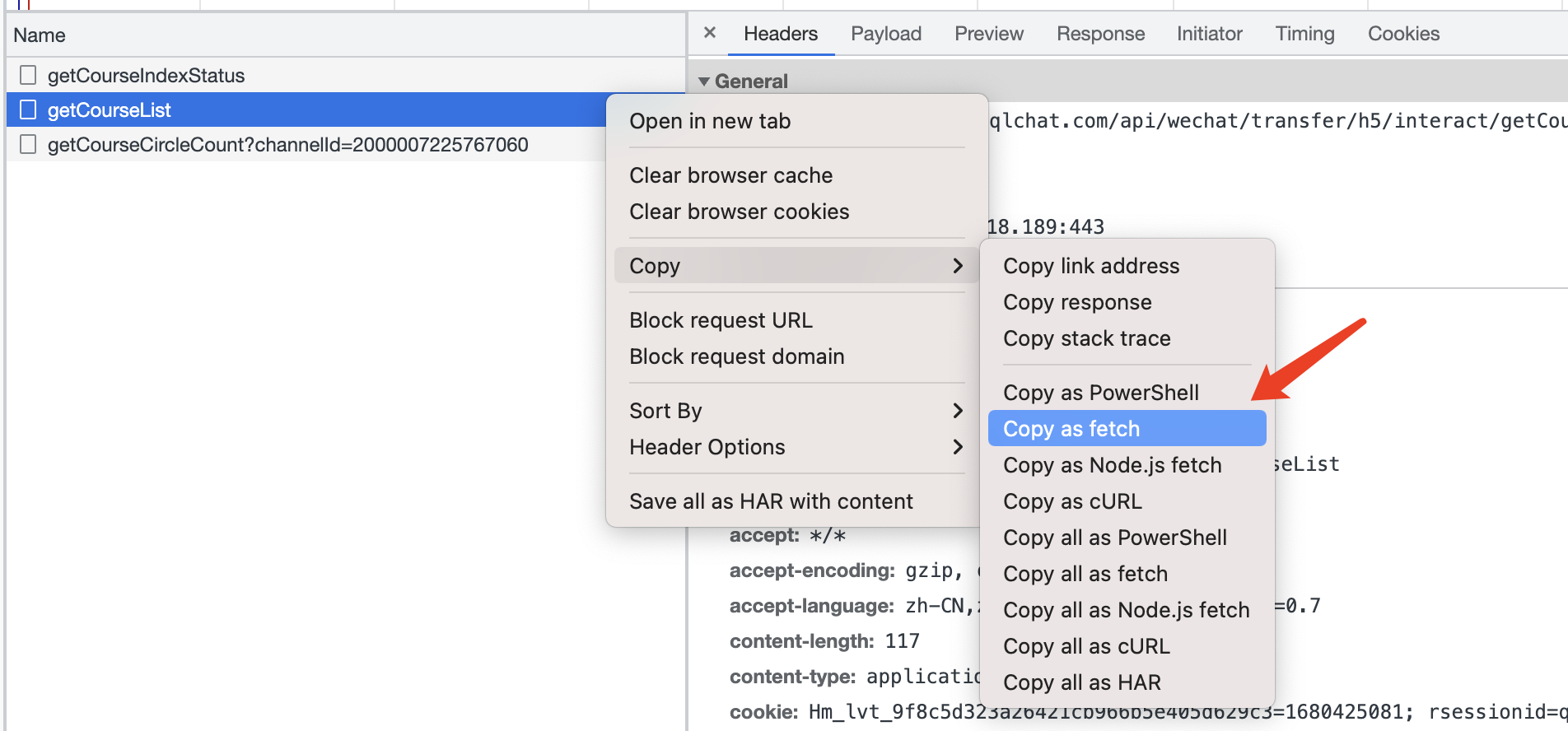
通过Chrome开发者工具,把请求复制出来,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| fetch("https://m.qlchat.com/api/wechat/transfer/h5/interact/getCourseList", {
"headers": {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7",
"content-type": "application/json;charset=UTF-8",
"sec-ch-ua": "\"Google Chrome\";v=\"111\", \"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"111\"",
"sec-ch-ua-mobile": "?1",
"sec-ch-ua-platform": "\"Android\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin"
},
"referrer": "https://m.qlchat.com/wechat/page/channel-intro?channelId=2000007225767060",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": "{\"channelId\":\"2000007225767060\",\"sort\":\"asc\",\"page\":{\"page\":1,\"size\":20}}",
"method": "POST",
"mode": "cors",
"credentials": "include"
});
|
里面有个关键信息,page可以控制分页,size默认是20,你当然也可以改成100或者其他数值。配合page字段,就可以把所有章节的信息抓出来了。当然也可以用copy as cURL,然后通过Python去请求cURL的命令,同样也可以把所有的章节信息抓到。获取章节信息是不需要登录的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| curl 'https://m.qlchat.com/api/wechat/transfer/h5/interact/getCourseList' \
-H 'authority: m.qlchat.com' \
-H 'accept: */*' \
-H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,zh-TW;q=0.7' \
-H 'content-type: application/json;charset=UTF-8' \
-H 'dnt: 1' \
-H 'origin: https://m.qlchat.com' \
-H 'referer: https://m.qlchat.com/wechat/page/channel-intro?channelId=2000007225767060' \
-H 'sec-ch-ua: "Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"' \
-H 'sec-ch-ua-mobile: ?1' \
-H 'sec-ch-ua-platform: "Android"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'user-agent: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Mobile Safari/537.36' \
--data-raw '{"channelId":"2000007225767060","businessId":"","liveId":"2000007225766924","sort":"asc","page":{"page":1,"size":20}}' \
--compressed
|
自动获取音视频链接
这是最关键的一步。因为如果手工打开网页一个一个去下载,那就太麻烦了。所幸有个很强大的工具叫Selenium,它是一个自动化web测试工具,可以模拟打开任何一个链接,并能记录下所有的日志信息,Chrome dev tools能拿到的日志,它也能拿到。废话不多说,直接上代码,先拿到登录cookie:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def save_cookie(url):
chrome_options = Options()
caps = {
'goog:loggingPrefs': {
'performance': 'ALL',
}
}
driver = webdriver.Chrome(desired_capabilities=caps, options=chrome_options)
driver.get(url)
time.sleep(30)
cookies = driver.get_cookies()
with open('cookie.json', 'w') as f:
f.write(json.dumps(cookies))
|
之后再通过Python+Selenium打开网页,自动带上Cookie就可以了。下方是获取音频链接的关键代码,得到章节id列表后,依次遍历,拼接URL:https://m.qlchat.com/topic/details-listening?topicId=章节id。 即可获取所有的音频链接,视频也是同样的道理,这里就不再赘述了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| def get_mp3_url(url):
"""
获取mp3下载链接
"""
chrome_options = Options()
# headless 表示不会启动 Chrome 窗口,但是内存是有数据的
chrome_options.add_argument('--headless')
# chrome_options.add_experimental_option('w3c', False)
caps = {
'goog:loggingPrefs': {
'performance': 'ALL',
}
}
driver = webdriver.Chrome(desired_capabilities=caps, options=chrome_options)
# 用浏览器打开 url
driver.get(url)
# 停留1秒,如果是第一次登录,可以改成30秒,等登录成功后,将cookie保存到文件中,下次直接用cookie登录
time.sleep(1)
# 删除所有cookie信息
driver.delete_all_cookies()
# 把之前保存的cookie读出来
with open('cookie.json', 'r', encoding='utf-8') as f:
cookie_list = json.loads(f.read())
# 将cookie添加到当前 chrome 页面中
for cookie in cookie_list:
driver.add_cookie(cookie)
# 重新打开 URL,此时的URL已经是登录后的了
driver.get(url)
# 停留三秒,页面大概率已经加载完毕了
time.sleep(3)
# 读取 Chrome 里的 Log 信息,筛选出我们需要的链接
for log in driver.get_log('performance'):
x = json.loads(log['message'])['message']
if x["method"] == "Network.requestWillBeSent":
download_url = x["params"]["request"]["url"]
if ".mp3" in download_url:
driver.close()
driver.quit()
return download_url
else:
pass
driver.close()
driver.quit()
return ""
|
经过上述操作,就可以把文件全部下载下来了。
这里需要注意的是视频是ts文件,需要全部下载下来之后,再拼接起来。Mac上拼接ts文件不是什么难事,用下方命令可将ts文件拼接起来
1
| cat 1.ts 2.ts 3.ts 4.ts > 001.ts
|
当然,如果想把ts文件转成mp3也是比较轻松的,直接用brew 安装好ffmpeg(brew install ffpmeg),然后执行如下指令即可
1
2
3
4
5
|
ffmpeg -i source.ts -f mp3 target.mp3
for i in *.ts; do echo"${i%.*}.mp3"; ffmpeg -i "$i" "${i%.*}.mp3";done
|
0x05 踩坑
错误1
1
| python invalid argument: log type 'performance' not found
|
解决:把参数loggingPrefs改成goog:loggingPrefs即可。
https://stackoverflow.com/questions/56507652/selenium-chrome-cant-see-browser-logs-invalidargumentexception
错误2
一开始思路错了,想通过js去做爬虫,因为能够直接Chrome登录,没有cookie的问题。但是始终没法在js代码里获取到所有的请求链接,最终只能作罢。换Python模拟登录的方案。
0x06 总结
经过一番折腾,终于把所有课程都下载下来了。这里面还是有不少坑的,比如音频文件链接请求返回206,不完整,需要改请求range参数,或者先发一次请求获取文件完整大小,再去分段下载;视频文件是ts文件,需要将所有的ts分片下载,然后拼接到一块等等。以及开发过程中的各种错误,都需要一点一点克服。
0x07 参考

